Private and Local AI Chatbot and Coding Assistant
Posted on Sat 30 November 2024 in articles
Introduction
This post will cover using Ollama to run a local, privacy-respecting AI chatbot and coding assistant, powered by popular open-source large language models.
I am not an expert and this will certainly not be the most ideal or performant setup for everyone. Instead, I am focussing on a path-of-least-resistance to two practical use cases, while covering the ease of setup on both older and newer systems.
Here, I will be using two systems:
- a new M4 Pro Apple Mac Mini running Homebrew
- an old Intel i7-4770 Fedora Linux server with a single Nvidia 1080 GPU
To follow along with this post, you will need:
- VRAM >= the size of the model you plan to run on your Ollama system - more information here.
- A Docker environment on the same system, or in the same local network, where you will be running Ollama
Installing and Configuring Ollama
Mac
brew install ollama
Fedora
curl -fsSL https://ollama.com/install.sh | sh
Note: On my system, while I had an updated Nvidia driver installed, Ollama was still not using the GPU, so I had to edit the service and hardcode a reference to it:
sudo nano /etc/systemd/system/ollama.service
Under the [Service] section, add this line:
Environment="CUDA_VISIBLE_DEVICES=0"
Note: I only have a single GPU on this system, so ‘0’ did the trick, but you can also use the UUID of your specific GPU.
Ollama should now be installed and running as a service.
Save the changes and restart the service:
sudo systemctl restart ollama.service
Moving forward, there is no difference between the systems in terms of interacting with ollama
Downloading a Model and CLI Demo
Download a model - there are various options to consider, but to start we’ll use Google’s gemma2 with 9 billion parameters (and 5.4gb in size):
ollama pull gemma2:9b
Run the model:
ollama run gemma2:9b
This command starts both a local API suite and CLI chatbot:
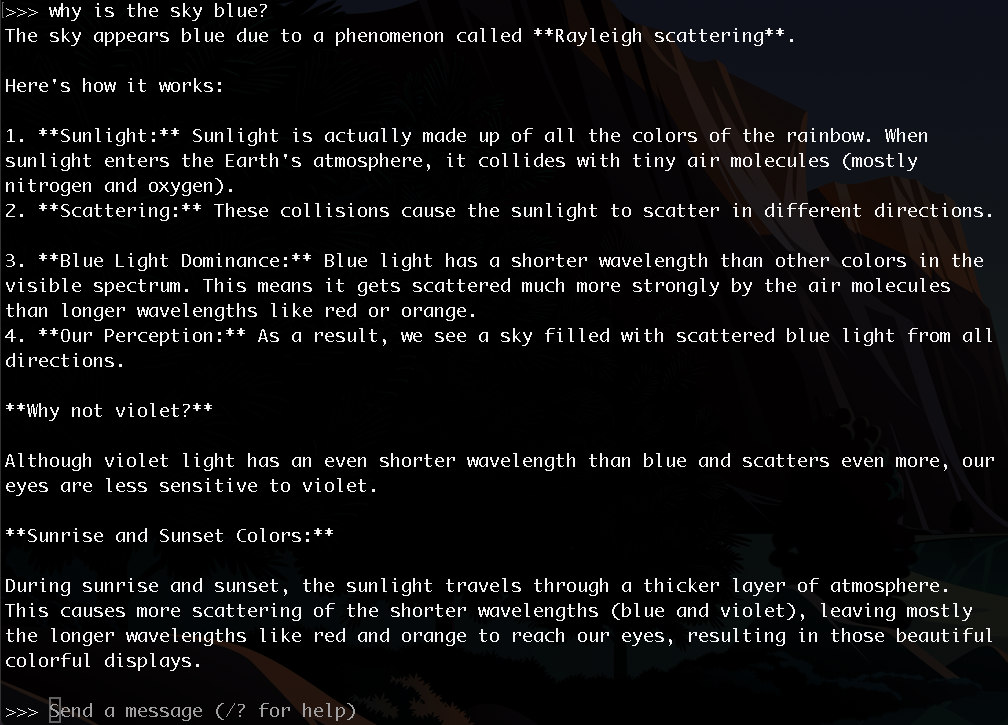
An advanced chatbot with Open WebUI
Open WebUI provides a browser-based gui that extends the functionality of ollama.
Pull and run it via Docker:
docker pull ghcr.io/open-webui/open-webui:main
docker run -d -p 3000:8080 -v open-webui:/app/backend/data --name open-webui ghcr.io/open-webui/open-webui:main
Via a browser, connect to Open WebUI at http://localhost:3000
You will need to create an account - while Open WebUI uses email address as a username, this remains a local installation.
After initial account setup, you will have a fully-functional, private chatbot:
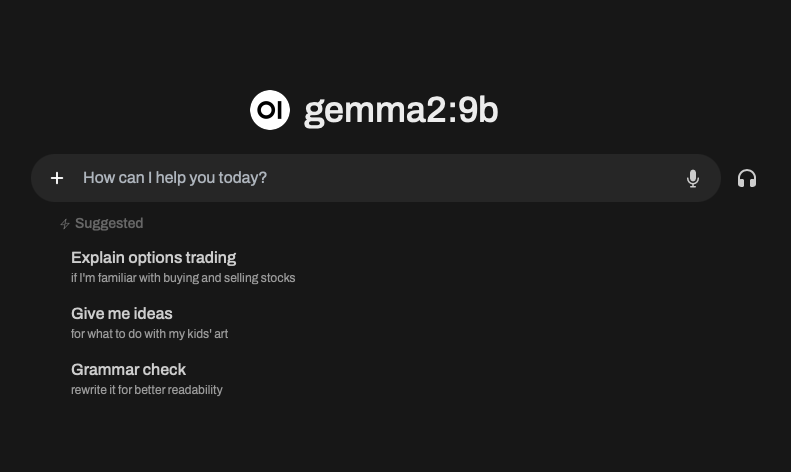
There is a lot to explore - for example, you can create multiple local users and download multiple models. Also of note, you can upload and have the models parse/process/analyze files (e.g. using the llama3.2-vision model to assist with OSINT image-based challenges.)
Full documentation can be found here.
A coding assistant with CodeGPT in PyCharm
This section assumes PyCharm is running either on the same system as Ollama, or on one that is accessible on the same local network.
First, go back to the CLI and pull a code-specific model:
ollama pull qwen2.5-coder:7b
Then in PyCharm:
Settings -> Plugins: search for and Download CodeGPT.
Followed by:
Settings -> Tools -> CodeGPT -> Providers -> Ollama(Local): Select the qwen coder model, Apply changes.
Moving forward, PyCharm will both autocomplete code and provide an interface for code review and explanation using your local model(s):
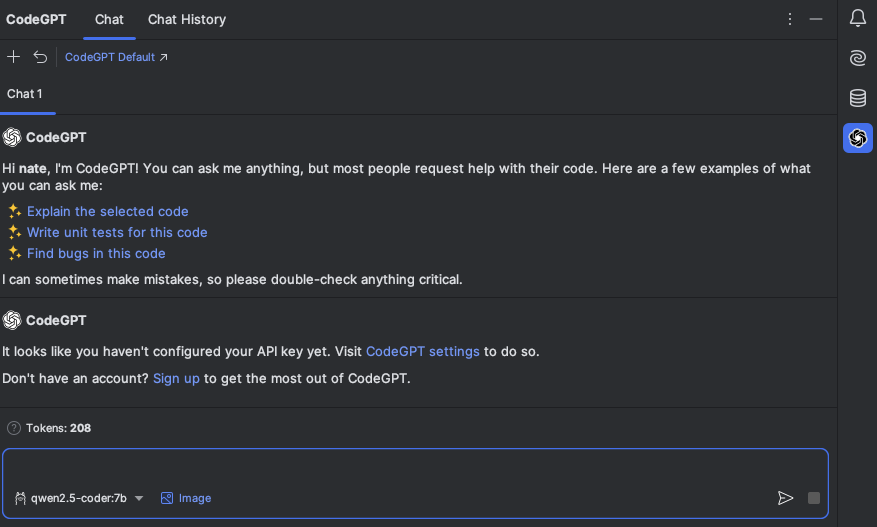
Additional documentation on CodeGPT for PyCharm can be found here.
Wrapping Up
Did you find this useful? Did you run into any setup issues or do you an have alternative setup? What other use cases are you exploring? Let me know via email or on Bluesky!